
Large language models (LLM) are form of artificial intelligence (AI) program that understand, summarize, generate, and predict new material using deep learning techniques and extremely huge data sets.
A language model performs a similar role in the AI realm, providing a foundation for communication and the generation of new concepts.
In this article, let’s take a closer look at everything about Large language models.
How do large language models work?

LLMs use a complicated technique with numerous components.
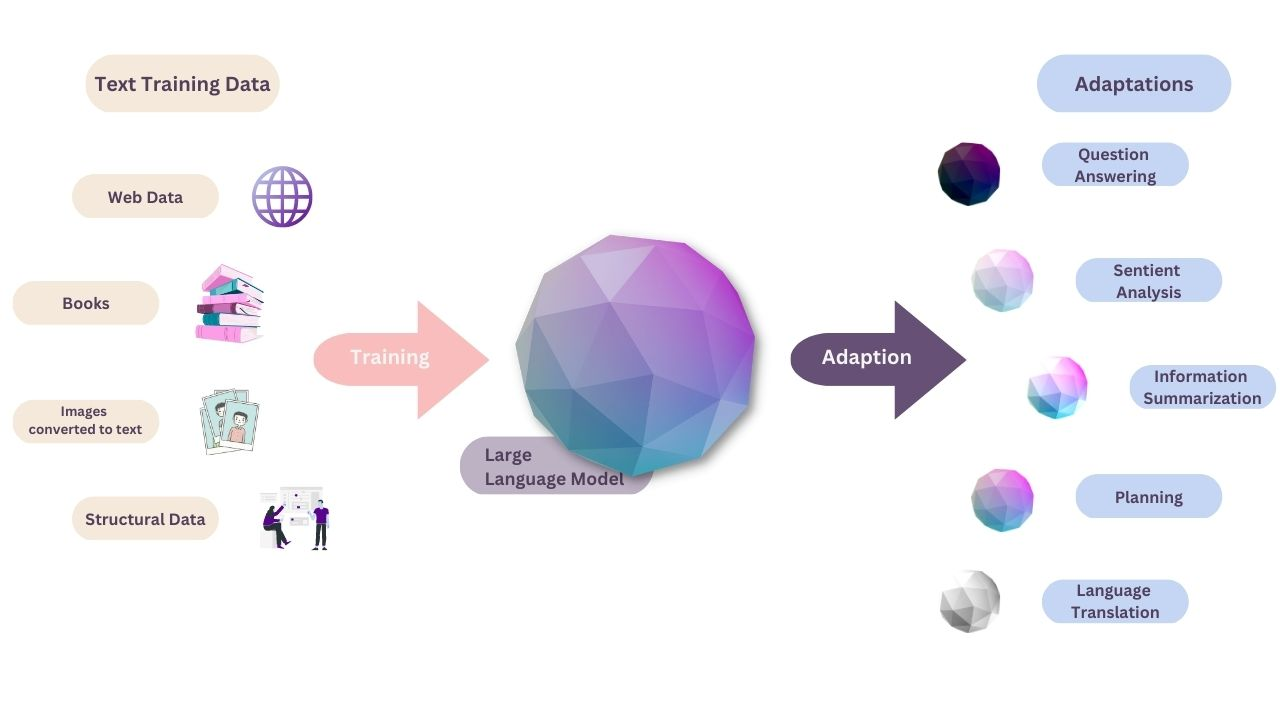
An LLM needs to be trained at the fundamental layer on a large volume of data, commonly referred to as a corpus, that is generally petabytes in size. The training might involve several phases, generally beginning with unsupervised learning.
This way, the model is trained on unstructured and unlabeled data. The advantage of training on unlabeled data is that there is extremely more data available. At this point, the model begins to infer links between different words and ideas.
Training and fine-tuning with self-supervised learning is the next stage for certain LLMs. Some data labeling has occurred here, improving the model in identifying many ideas more precisely.
The LLM then passes through the transformer neural network procedure, which involves deep learning. Using a self-attention mechanism, the transformer architecture enables the LLM to learn and identify the linkages and connections between words and concepts.
To identify the relationship, that mechanism can assign a score, also known as a weight, to a specific object (called a token).
After an LLM has been trained, a foundation exists for the AI to be used for practical purposes. The AI model inference can create a response by questioning the LLM with a prompt, which might be an answer to a question, freshly generated text, summary text, or sentiment analysis.
When do we use large language models?

LLMs have been famous thanks to their extensive application for a range of NLP tasks, including the following:
- Text creation. A fundamental use case is the capacity to create text on any topic on which the LLM has been educated.
- Translation. The capacity to translate from one language to another is a frequent attribute of LLMs trained in many languages.
- Content summary. LLMs can summarize sections of text or multiple pages.
- Content rewriting. Another skill is its ability to rewrite a chunk of text.
- Categorization and classification. An LLM can classify and categorize information.
- Analysis of sentiment. Most LLMs can be used for sentiment analysis, which can assist users in better understanding the purpose of a piece of text or a specific answer.
- Chatbots and conversational AI. LLMs can enable more natural communication with a user than previous generations of AI systems.
A chatbot, which exists in different forms where a user interacts in a query-and-response manner, is one of the most frequent uses for conversational AI. ChatGPT, which is built on OpenAI’s GPT-3 model, is one of the most extensively used LLM-based AI chatbots.
The advantages of large language models:
Users can benefit advantages from LLMs, including:
- Adaptability and extensibility. We can use LLMs to build specific use cases. Additional training on top of an LLM can bring a finely customized model for the specific demands.
- Flexibility. One LLM can handle a wide range of tasks and deployments across companies, users, and apps.
- Performance. Modern LLMs are often high-performing, it’s capable of producing quick, low-latency replies.
- Accuracy. The transformer model may give higher accuracy if the number of parameters and volume of learned data increase in an LLM.
- Effortless training. Many LLMs are trained on unlabeled data, which speeds up the learning process.
Some drawbacks of large language models
While there are several benefits of adopting LLMs, there are some obstacles and limitations:
- Costs of development. LLMs often demand a large amount of expensive graphics processing unit technology and massive data sets to execute.
- Costs of operations. The cost of running an LLM for the host company beyond the training and development period might be quite high.
- Bias. Bias is a danger with any AI trained on unlabeled data since it is not always clear that recognized bias has been eliminated.
- Explainability. Users do not find it clear or specific to describe how an LLM generated a given result.
- Hallucination. When an LLM produces an incorrect response that is not based on taught data, this is referred to as AI hallucination.
- Complexity. Modern LLMs are extremely intricate technology with billions of parameters that are quite difficult to debug.
- Tokens for glitches. Since 2022, maliciously crafted prompts that cause an LLM to malfunction, called glitch tokens, and it has become a developing trend.
Types of large language models
The many sorts of big language models use a growing collection of words. The following are examples:
- No shots model. This is a huge, generalized model trained on a generic corpus of data that may provide a reasonably accurate result for general use scenarios without further training. GPT-3 is frequently regarded as a zero-shot model.
- Fine-tuned or domain-specific models. Additional training on top of a zero-shot model, such as GPT-3, can result in a domain-specific model. One example is OpenAI Codex, a GPT-3-based domain-specific LLM for programming.
- Language representation model. Bidirectional Encoder Representations from Transformers (BERT) is one example of a language representation model that uses deep learning and transformers ideally suited for NLP.
- Multimode model. LLMs were originally designed to handle only text, but with the multimodal approach, they can now manage both text and graphics. GPT-4 is one example of this.
Conclusion
The future of LLM is still being developed by the humans who build the technology, however, there may come a day when LLMs write themselves. The next generation of LLMs will most likely not have artificial general intelligence or be sentient in any way, but they will constantly grow and become “smarter.”
LLMs will continue to be trained on greater and larger volumes of data, with the data becoming progressively vetted for accuracy and possible bias. It’s also conceivable that future LLMs will outperform the present generation in terms of giving attribution and greater explanations for how a specific outcome was achieved.
Another conceivable future direction for LLMs is to enable more precise information for domain-specific knowledge. There is also a class of LLMs based on the concept of knowledge retrieval, such as Google’s REALM (Retrieval-Augmented Language Model), that allows training and inference on a very narrow corpus of data, similar to how a user can exactly search information on a single site.
There is also ongoing research to reduce the total size and training time required for LLMs, such as Meta’s LLaMA (Large Language Model Meta AI), which is smaller than GPT-3 but, according to its supporters, is more accurate.
The future of LLMs is so bright as technology will keep progressing in ways that can boost human efficiency.